Lab Note: Multiple readouts from ViT models
In a previous post I showed, in the context of vision transformers on imagenet, that information about labels is present in the CLS tokens of layers throughout the network, but this information is not used by the final network outputs. This lead to a loose mental model of ViT classifiers: Rather than gradual accumulation of label information into the CLS token, the network produces ‘expressive’ image tokens that are able to strongly separate classes, regardless of the CLS tokens that they are paired with. Here we investigate this model further, along with the feasibility of using multiple such readouts from a ViT model.
Label information restoration after CLS shuffling
First, we measure how quickly label information is read back into the CLS tokens after randomization. We batch-shuffle the CLS tokens (in batches with heterogeneous labels) within a single layer of the network, and assess the accuracy of linear probes (that were fit on un-shuffled data) at every layer.
This experiment used the base ViT google/vit-base-patch16-224, and small version of imagenet zh-plus/tiny-imagenet, with 200 classes and down-sized images.
Below, each panel shows the accuracy of linear probes on a single layer of the network. The x-axis denotes which layer has had its CLS tokens randomized.
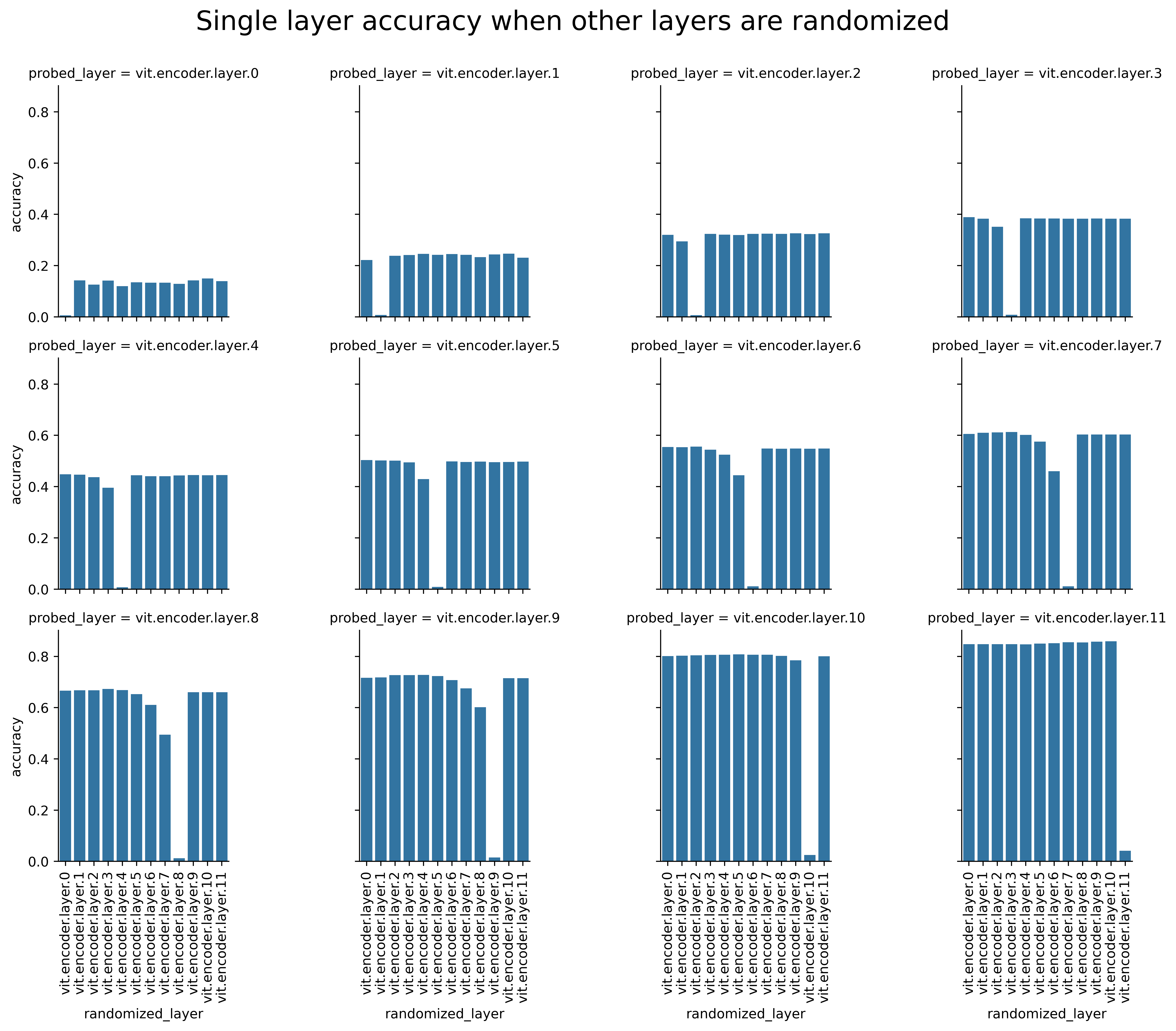
Note that for each layer, randomization of the CLS tokens in that layer causes the probe accuracy to drop to close to random. At the same time, randomization of layers after (higher indices than) the probed layer has no impact on the activity in that layer, so the accuracy at the probed layer is constant. The key question is how CLS randomization in layers before the probed layer impacts its accuracy. The earliest and latest layers of the network appear relatively immune to randomization, even up to the directly preceding layers. The middle layers, meanwhile, show more sensitivity that extends back earlier in the network. This suggests that some label information (at least the label information that these probes pick up on) does gradually accumulate in the CLS tokens in the middle of the network.
I’m not sure quite what to make of this result in terms of interpretability questions. Loosely speaking, it seems to imply that, while the information in CLS tokens is used in the network’s computations, the model is also robust enough, and the information distributed enough, that the impact of shuffling can be undone. Following that train of thought suggests that it is unlikely that the CLS token probes reflect information that is not replicated elsewhere in the network, due to the distributed nature of the representation. We can think about them loosely as indicators for the final output: both are jointly conditional on the image token information.
On a practical level, the direct dependence between the CLS tokens in adjacent layers of the network demonstrates that getting multiple independent readouts from the network layers is not as simple randomizing the CLS token between layers, since this would hamper the performance of adjacent probes.
Readouts from of the network with randomly selected CLS tokens
Given both our mental model of ViTs as producing expressive readouts on arbitrary CLS tokens, and the previous result showing that randomization is detrimental to internal CLS readouts, we explore alternative readout strategies for ViT layers. Rather than randomizing tokens during the forward pass, we leave the forward pass unaltered, and simply track the token inputs to layers of interest. We then replace the CLS tokens in the inputs to the layers of interest using randomly sampled tokens, pass everything through the layer, and decode labels from the output CLS tokens. We learn both the input token distribution and the MLP decoder.
In other words, we ask how well layers of the model can use their image tokens to decode random CLS tokens from the best-case CLS token distribution.
Below we show the test accuracy for last four transformer layers, 8-11, of a dinov2 model facebook/dinov2-base with training and test data from a subset of imagenet-1k.
In blue we show the performance of an MLP decoder with CLS tokens unaltered.
In orange, we fit the input CLS token distribution and use this to replace the CLS tokens from the forward model.
Finally, in green, we still fit an input CLS distribution, but, rather than replacing the CLS tokens, we instead insert the random token as the new 0th token, which is then decoded by the model.
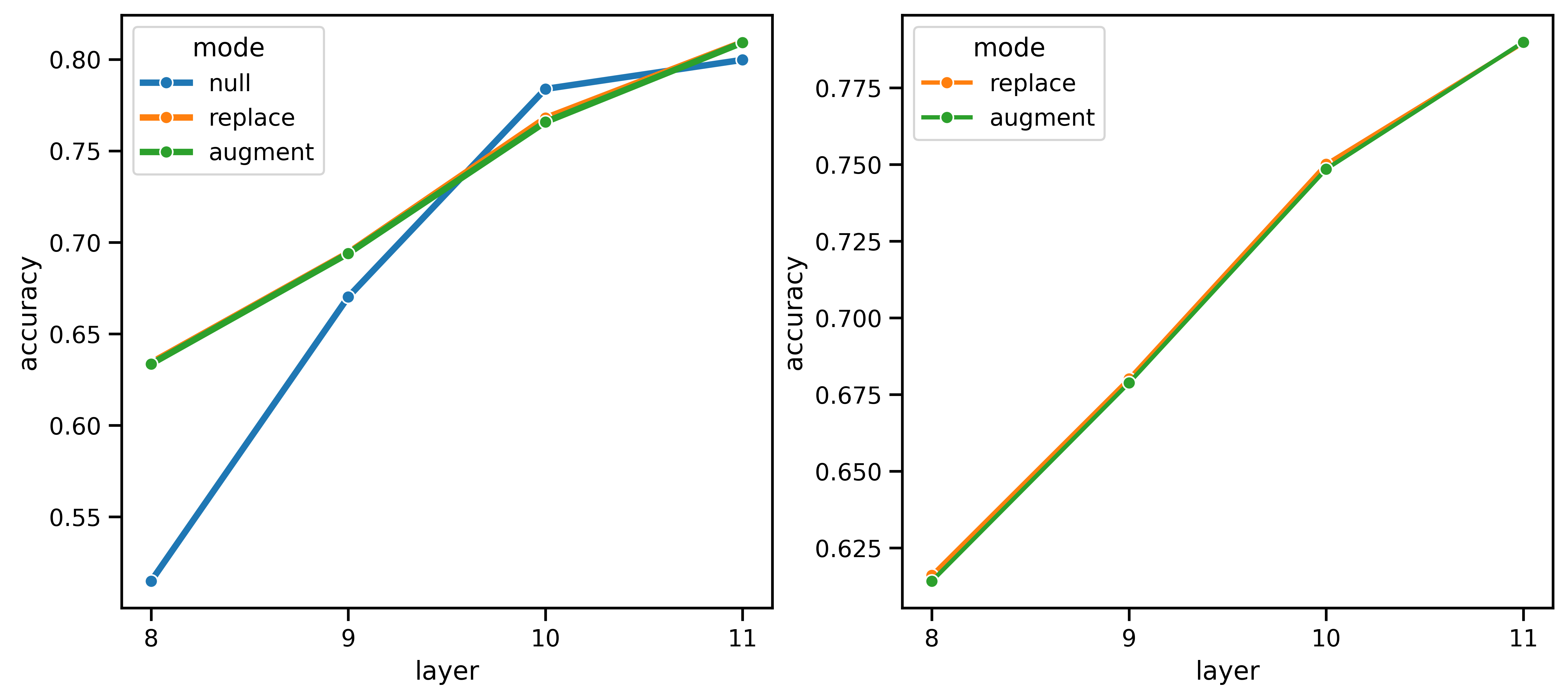
Blue is the control baseline, which uses the information in the CLS tokens. Green shows the impact of removing this information in favor of random tokens, and reading out from them. Orange keeps the information in the CLS tokens, but requires that it be read-out through random tokens.
Note that replacement and augmentation (orange and green) are almost identical, with a replacement consistently performing slightly better (right panel). This performance difference is within the range of what hyper-parameter optimization could achieve, so these can be considered equal. This indicates that, for a single transformer step, having the CLS token alongside the image tokens provides little additional benefit to random read-outs. Relative to the null, which leaves the CLS tokens unmodified, the alternate read-out methods do show large accuracy differences. They are substantially more accurate at the lower layers, but lose-out on the accuracy advantage at the higher layers. This indicates two key points: 1) In the earlier layers, the internal CLS tokens are not well suited to reading-out the information in the image tokens, and 2) in the later layers, the internal CLS tokens become competitive with, and can exceed the performance of randomized read-outs.
These results are somewhat preliminary. The training hyper-parameters are not optimized in any case, and the models show continuous improvement in validation accuracy through training. This, along with comparable performance with fewer epochs of training, indicates that improvements can be made to learning rate scheduling. One consequential choice was weight initialization. The above runs re-used the weights learned for layer-10 to initialize the weights in the other runs. As we can see below, relative to de-novo initialization, this choice is helpful for the performance at early layers, but harmful to layer 11 performance (at least in the null case).
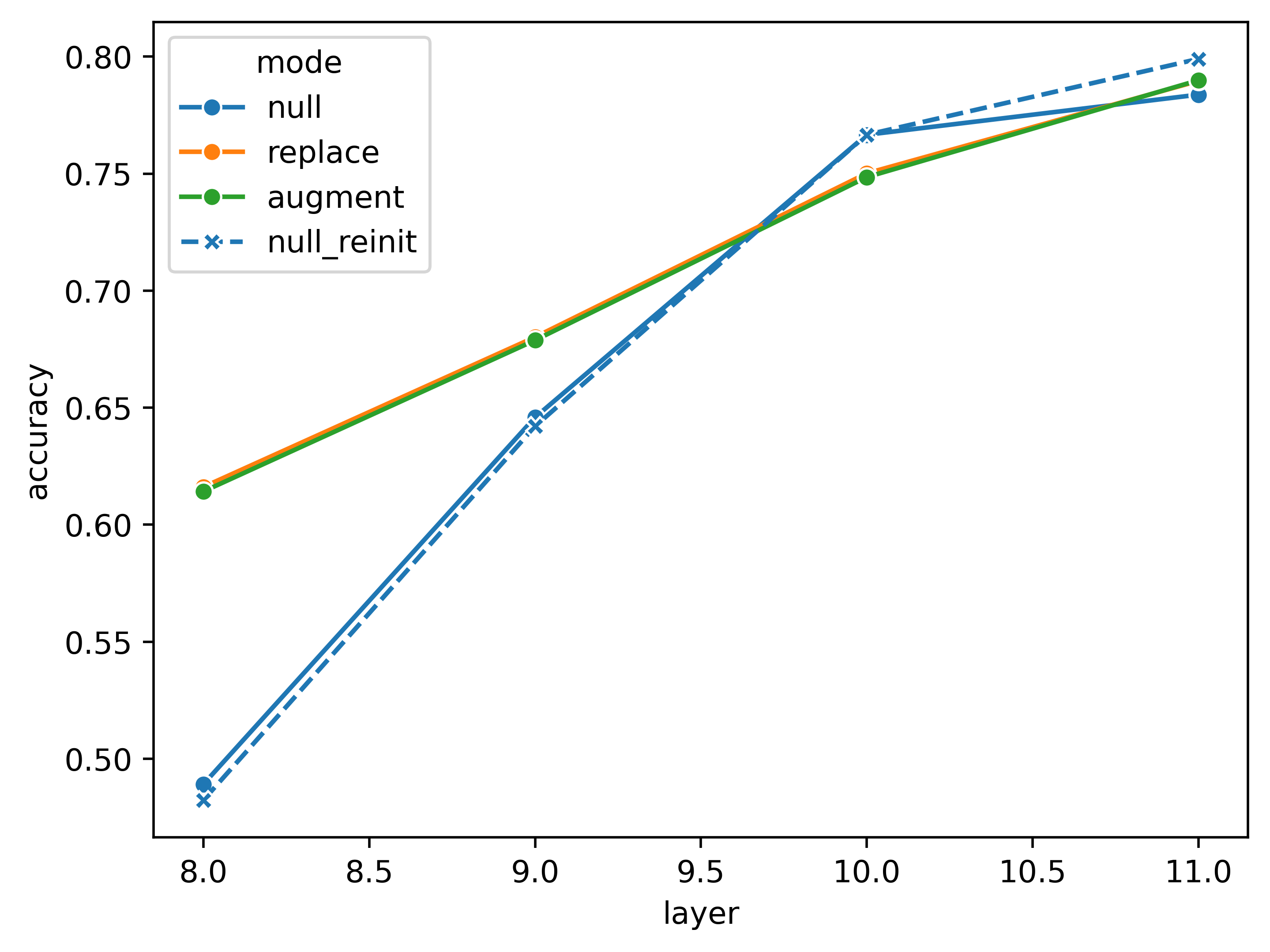
Even taking these caveats into consideration, these results support the idea of internal class tokens as facilitating the computations happening in these layers, rather than accumulating label information: randomized CLS tokens perform better than the internal ones when use for decoding. The last two layers, on the other hand, show CLS tokens that are just as good or better than (optimized) random tokens at reading out the information in image tokens. These CLS tokens are at minimum well-behaved for read-outs. Where they out-perform random CLS tokens, they can even be argued to contain label-specific information: they out-perform by virtue CLS-image token pairings. The failure of randomized readouts of CLS + image token (‘augment’) to outperform randomized read-outs of image tokens alone (‘replace’) provides evidence that the information found in CLS tokens is also distributed through the image tokens. Finally, it is worth ending on a practical note: with the right CLS token distribution, we can achieve internal readouts with fairly good accuracy, even at layer 8.
Related work:
See the my next post in this project here.